Context¶
The Synthetic Data tools are used to build code that creates useful data. The goal is to create large volumes of data that generally match detailed schema specifications.
Additionally, invalid values can be injected to create examples of low-quality data.
We’ll start with the conventional use case of valid data.
Creating Valid Data¶
The valid data is written by an application that leverages the Data Synth tool. Development mostly happens in an IDE, importing and extending the tool. The resulting application creates the data.
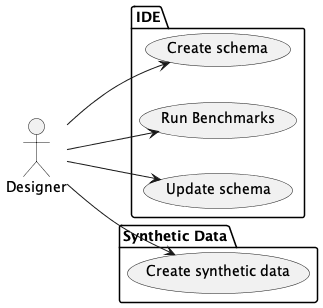
The general workflow has a number of steps.
Create a very detailed schema using
pydantic. This will include details beyond those conventionally used for validation. For example, a distribution shape (uniform, normal, exponential, Benford, etc.) may also be needed.Use the schema to create synthetic data.
Use the synthetic data to create benchmark results of running real (or spike solution) software on real hardware with realistic data.
Update the schema to create “better” data. Often, the distributions, and optionality settings need tweaking. Also, customized synthesizers may be required. As more is learned about the algorithms, the problem domain, and the user stories, more sophisticated data is required.
Recreate the data. Rerun the benchmarks. Repeat as needed.
Here’s an activity diagram:
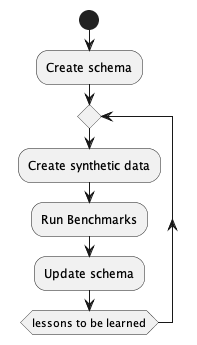
The “Run Benchmarks” is intentionally open-eneded.
For SQL Database Design, this often means loading a database and running queries. It may mean running batches of concurrent queries to guage performance under load. It may mean spinning up server farms to run large batches of queries. All of this is outside the tool. The tool synthesizes the data for controlled, reproducible, at-scale benchmarking.
The schema definition is explicitly aimed at creating a definition that’s usable by JSONSchema tools. See https://json-schema.org for more information on JSONSchema. The JSONSchema rules define a number of formats for string data. See https://json-schema.org/draft/2020-12/json-schema-validation#name-defined-formats for the list.
Beyond these formats, JSONSchema also supports regular expression patterns to define valid string values. This permits additional flexibility where needed.
The other common use case creates noisy, invalid or faulty data.
Creating Noisy Data¶
There are several tiers of noise:
The values are of the expected type and in the expected domain, but an unexpected distribution.
The values are of the expected type, but are outside the expected domain.
The values are not of the expected type.
The values do not fit the expected logical layout. This may mean a CSV file with extra or missing columns. It may mean a NDJSON file with unexpected fields.
The source files do not fit the expected physical format. For example, a CSV file has invalid or inconsistent comma and quote use. Or, a file that expected JSON documents contains a document not in JSON format.
This application deals with the first three tiers of invalid data.
Generally, a noise threshold is set. For some kinds of bulk performance testing, it might be a low 5% to assure 1 field value in 20 has invalid data. For a record with 20 fields, almost every record will have an error. A few will have multiple errors, a few will be error free.
For more complex documents with more fields, a lower noise threshold makes sense. For shorter documents with fewer fields, a higher noise threshold assures a useful mix of bad data.