funcsql Code¶
Here’s the content of the funcsql module.
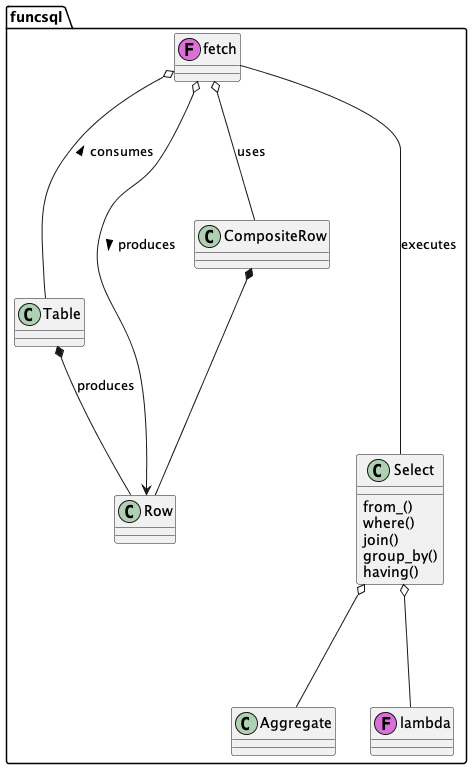
We’ll look at the funcsql.Table and funcsql.Row structures first.
Then the funcsql.Select class, used to define a query.
The funcsql.fetch() function embodies the Essential SQL Algorithm.
It executes the query object, consuming rows from tables and producing rows in a result.
Along the way, it builds funcsql.CompositeRow objects which are provided to lambdas to evaluate expressions.
Table and Row¶
The funcsql.Table objects contain the data to be processed.
The funcsql.Row is a wrapper that provides handy attribute name access for dictionary keys.
Table¶
- class funcsql.Table(name: str, data: Iterable[dict[str, Any]] | None = None, schema: list[str] | None = None)¶
The foundational collection of data consumed by a query.
A Table produces
funcsql.Rowobjects, but doesn’t necessarily contain them. The structure in this class is alist[dict[str, Any]]. From these,funcsql.Rowobjects are created.A table has an internal name that’s used by the query. This should match the Python variable name, but that’s not a requirement.
The external Python variable is only used in the
funcsql.Select.from_()method. The internal string name is used in all lambdas throughout the query.Example
>>> t = Table("t", [ ... {'col1': 'row1-colum1', 'col2': 42}, ... {'col1': 'row2-colum1', 'col2': 43}, ... ]) >>> list(t) [Row('t', **{'col1': 'row1-colum1', 'col2': 42}), Row('t', **{'col1': 'row2-colum1', 'col2': 43})]
Important
Table names must be valid Python identifiers.
Column names must be valid Python identifiers.
The data source for a table can can be raw (external) data or it could be results of query execution.
Subclasses can support a wide variety of collections.
list[list[str]] supplied with a schema (i.e. CSV reader + headers).
list[JSONDoc] with JSONSchema schema definition from NDJSON files.
- load(data: Iterable[dict[str, Any]]) None¶
Replace the underlying data with this data.
- column_names() list[str]¶
Expose the column names. Useful for
SELECT *constructs.
Row¶
- class funcsql.Row(table: str, **columns: Any)¶
An immutable collection of column names and values.
Subclasses can be created to wrap a variety of collections, including dataclasses or Pydantic
base_modelinstances.- _asdict() dict[str, Any]¶
Return the row as a dictionary.
- _values() list[Any]¶
Rerturn only the values from this row.
Select query builder¶
The funcsql.Select class is used by build queries (and subqueries.)
It’s used by the funcsql.fetch() function (among others) to consume rules from funcsql.Table objects
and produce an iterable sequence of funcsql.Row results.
The result of a funcsql.Select construction is a data structure to be used by the funcsql.fetch() function.
A funcsql.Select is iterable as a convenience.
Select¶
- class funcsql.Select(star_: str | None = None, **name_expr: Callable[[CompositeRow], Any] | Aggregate)¶
Builds a query, starting with the
SELECTclause.For
SELECT *queries, thestarparameter must beSTAR.For all other query forms, use
name=lambda cr: exprconstructs. This is equivalent toexpr AS namein SQL.The expression can contain
table.columnreferences usingcr.table.column. The full name must be provided: we don’t attempt to deduce the table that belongs with a name.The expression can contain any other Python literal of function.
SELECT label, 3*val+1 as answer, 42 as literal FROM table
Select( label=lambda cr:cr.table.label, answer=lambda cr: 3 * cr.table.val + 1, literal=lambda cr: 42 )
Each expression must be a function (or lambda or callable object) that accepts a single
funcsql.CompositeRowobject and returns a useful value.- from_(*tables: Table | str, **named_tables: Table | str) Self¶
The FROM clause: the tables to query. Table aliases aren’t required if all the table names are unique.
To do a self-Join, the tables require an alias. The alias will be used in CompositeRow objects.
SELECT e.name as employee, m.name as manager FROM employees e, employees m WHERE ...
( Select( employee=lambda cr: cr.e.name, manager=lambda cr: cr.m.name ) .from_(e=employees, m=employees) .where(...) )
This method also expands
SELECT *into proper names.For recursive queries in a
funcsql.Withcontext, a table is created by the initial query. This table recursively populated by afuncsql`Select.union()that references the named initial table using a string table name instead of afuncsql.Tableobject.
- join(table: Table | None = None, *, on_: Callable[[CompositeRow], bool], **alias: Table) Self¶
The JOIN table ON condition clause: a table to query and the join condition for that table.
SELECT e.name as employee, m.name as manager FROM employees e JOIN employee m ON e.manager_id = m.employee_id
( Select( employee=lambda cr: cr.e.name, manager=lambda cr: cr.m.name ) .from_(e=employees) .join(m=employee, on_=lambda cr: cr.e.manager_id == cr.m.employee_id) )
In principle, this could lead to an optimization where pair-wise table joins are done to build the final
CompositeRowobjects.This doesn’t handle any of the outer join operators.
Todo
[LEFT | RIGHT | FULL] OUTER? JOIN
An implicit union of non-matching rows. An additional “filterfalse()`` is required to provide NULL-filled missing rows.
Todo
USING("col1", "col2")buildslabmda cr: cr.table.col1 == cr.?.col1Based on left and right sides of
join(table, using=("col1", "col2")).
- where(function: Callable[[CompositeRow], bool]) Self¶
The WHERE clause: an expression used for joining and filtering.
SELECT e.name as employee, m.name as manager FROM employees e, employees m WHERE e.manager_id = m.employee_id
( Select( employee=lambda cr: cr.e.name, manager=lambda cr: cr.m.name ) .from_(e=employees, m=employees) .where(lambda cr: cr.e.manager_id == cr.m.employee_id) )
- group_by(*name: str, **named_expr: Callable[[CompositeRow], Any]) Self¶
The GROUP BY clause: a list of names or a list of name=expr expressions.
If names are provided, they must be names computed by the
SELECTclause.If name=expr is used, the name=expr is added to the
SELECTclause.SELECT deparment_id, count(*) FROM employees GROUP BY department_id
( Select( department_id=lambda cr: cr.employees.department_id count=Aggregate(count, "*") ) .from_(employees) .group_by("department_id") )
- having(function: Callable[[Row], bool]) Self¶
The HAVING clause: an expression to filter groups.
The expression will operate on
funcsql.Rowobjects. It does not operate onCompositeRowobjects.SELECT deparment_id, count(*) FROM employees GROUP BY department_id HAVING count(*) > 2
( Select( department_id=lambda cr: cr.employees.department_id count=Aggregate(count, "*") ) .from_(employees) .group_by("department_id") .having(lambda row: row.count > 2) )
The groups are not built from
CompositeRowobjects; they’re simplerfuncsql.Rowobjects.
Aggregate¶
Aggregate comptuations are done after grouping, and must be delayed until then.
To make this work out, they’re wrapped as an object that’s distinct from a simple lambda.
- class funcsql.Aggregate(reduction_function: Callable[[Iterable[Any]], Any], name: str | Callable[[CompositeRow], Any])¶
Wrapper for an aggregate function to summarize.
There are three forms for using this:
m_x = Aggregate(mean, "x"), x = lambda jr: jr.table.column
The
x=exprdefines the raw value to summarize. This value is then referred to by name in theAggregate()constructor. (Yes, thex=is defined later, but name resolution doesn’t happen until the query is run.)m_x = Aggregate(mean, lambda jr: jr.table.column)
Same as above. A column name is made up for the expression.
count = Aggregate(count, "*")
A special case.
Many SQL aggregates are first-class parts of Python.
AVG
statistics.mean()COUNT
We define a special
functsql.count()function to ignore None.MAX
max()MIN
min()SUM
sum()STDEV
statistics.stdev()Todo
Offer
DISTINCTvariants to reduce to a set before computation.
CompositeRow¶
These objects move through the funcsql.fetch() function’s pipeline of steps.
- class funcsql.CompositeRow(*table_rows: Row, context: CompositeRow | None = None)¶
A collection of
Rowinstances from one or more named Tables. This provides attribute navigation through the columns of the tables in this composite.>>> cr = CompositeRow(Row("t1", a=1), Row("t2", b=2)) >>> cr.t1.a 1 >>> cr.t2.b 2
SQL Algorithm¶
fetch¶
- funcsql.fetch(query: QueryBuilder, *, context: CompositeRow | None = None, cte: dict[str, Table] | None = None) Iterator[Row]¶
- funcsql.fetch(query: Select, *, context: CompositeRow | None = None, cte: dict[str, Table] | None = None) Iterator[Row]
- funcsql.fetch(query: Values, *, context: CompositeRow | None = None, cte: dict[str, Table] | None = None) Iterator[Row]
- funcsql.fetch(query: With, *, context: CompositeRow | None = None, cte: dict[str, Table] | None = None) Iterator[Row]
The essential SQL Algorithm.
For
SELECT, the algorithm is this:\[Q(T) = H \biggl( G \Bigl( S \left( W ( F(T) ) \right) \Bigr) \biggr)\]For
VALUES, the algorithm is much smaller:\[Q() = S( \bot )\]Where
\(H\) is
funcsql.from_product().\(G\) is
funcsql.group_reduce(), which usesfuncsql.aggregate_map().\(S\) is
funcsql.select_map()that evalutes expressions.\(W\) is
funcsql.where_filter().\(F\) is
funcsql.from_product().and \(\bot\) is a placeholder non-empty result.
Reading from inner to outer, the order of operations is:
FROM – Creates table-like creature with
CompositeRowrows.WHERE – filters
CompositeRowrows.SELECT – creates a
Tablewith simpleRowinstances, but no name.GROUP BY – creates a second table with
Rowinstances and no name.HAVING – filters the second table
- Parameters:
query – The
QueryBuilderthat provides Row instances.context – A context used for subqueries that depend on a context query.
cte – The Common Table Expression tables, built by the preceeding
WITHclause.
- Returns:
Row instances.
Todo
Refactor to return
Iterator | Noneor raise an exception.It’s awkward to test an Iterator. It’s easier to test the class (None or Iterator) or handle an exception.
- funcsql.exists(context: CompositeRow, query: Select) bool¶
Did a suquery fetch any rows? Implements the
EXISTS()function.- Parameters:
context – A context used for subqueries that depend on a context query.
query – The Query that provides Row instances.
- Returns:
True if any row was built by the query.
Note
The order of the arguments is reversed from
funcsql.fetch()because this is used in a query builder where a context is generally required.
fetch values¶
component functions¶
- funcsql.from_product(query: Select, *, context: CompositeRow | None = None, cte: dict[str, Table] | None = None) Iterable[CompositeRow]¶
FROM clause creates an iterable of
funcsql.CompositeRowobjects as a product of source tables.- Parameters:
query – The
funcsql.Selectobjectcontext – An optional context used for subqueries.
- Returns:
product of all rows of all tables
- funcsql.where_filter(query: Select, composites: Iterable[CompositeRow]) Iterator[CompositeRow]¶
WHERE clause filters the iterable
funcsql.CompositeRowobjects.- Parameters:
query – The
funcsql.Selectobjectcomposites – An iterable source of
funcsql.CompositeRowobjects
- Returns:
An iterator overn
funcsql.CompositeRowobjects.
Todo
Outer Joins are implemented here.
- funcsql.select_map(query: Select | Values, composites: Iterable[CompositeRow]) Iterator[Row]¶
SELECT clause applies all non-aggregate computations to the
funcsql.CompositeRowobjects.- Parameters:
query – The
funcsql.Selectobjectcomposites – An iterable source of
funcsql.CompositeRowobjects
- Returns:
an iterator over
funcsql.Rowinstances.
- funcsql.aggregate_map(select_clause_agg: dict[str, Aggregate], groups: dict[tuple[Any, ...], Iterable[Row]]) Iterator[Row]¶
Applies
Aggregatecomputations to grouped rows.Very similar to the way the
funcsql.select_map()function works.- Parameters:
select_clause_agg – the aggregate functions from a
funcsql.Selectobjectgroups – the key: list[value] mapping with groups built from raw data.
- Returns:
an iterator over
funcsql.Rowinstances.
- funcsql.group_reduce(query: Select, select_rows: Iterable[Row]) Iterator[Row]¶
GROUP BY clause either creates groups and summaries, or passes data through.
There are three cases:
Group by with no aggregate functions. This will be a collection of group keys.
Aggregate functions with no Group by. This is a single summary aggregate applied to all data. Think
SELECT COUNT(*) FROM table.Neither Group by nor aggregate functions. The data passes through.
- Parameters:
query – The
funcsql.Selectobjectselect_rows – iterable sequence of
funcsql.Rowobjects
- Returns:
iterator over
funcsql.Rowobjects
Todo
Avoid simple
list()in order to cope with partitioned tables.
- funcsql.having_filter(query: Select, group_rows: Iterable[Row]) Iterator[Row]¶
HAVING clause filters the groups.
This is similar to
funcsql.where_filter().- Parameters:
query – The
funcsql.Selectobjectselect_rows – iterable sequence of
funcsql.Rowobjects
- Returns:
iterator over
funcsql.Rowobjects
Other SQL¶
These perform the expected operation on the underlying funcsql.Table.
It’s often better to reach into the Table directly.
The point of the funcsql.Table class is to wrap an underlying Python data structure.
- class funcsql.Insert¶
Adds rows to a Table.
Insert().into(table).values([{data}])
- class funcsql.Update(table: Table)¶
Updates rows in a Table.
( Update(table) .set(col=lambda row: function) .where(lambda row: condition) )
- class funcsql.Delete¶
Deletes rows from a table.
Delete().from_(table).where(lambda row: condition)