I'm struggling with brain cramps trying to understand something my past self wrote. Current me needs to go outside and do something that doesn't involve software or complexity. Sadly, current me is trying to make one small change and it feels like the software has passed out of the realm of manageable complexity into that space of unknowable chaos. Considering the heliopause, I feel like there's a simpli-pause out there, and I'm drifting past it.
BLUF (TL;DR)
There is no big, simple lesson up front. Except, maybe this: "Simplicity requires hard work."
Or maybe quote Pascal's apology:
I have made this longer than usual because I have not had time to make it shorter.
I think complexity stems from failure to budget enough time to find the useful patterns and simplify.
What concrete steps can we take to simplify? Read on.
Context
See https://github.com/cloud-custodian/cel-python for the code base.
We have the following conceptual model.
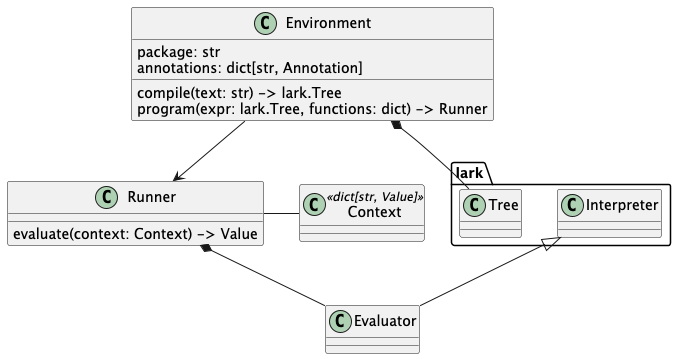
An overview of some of the classes. There's more. Too much more.
The application will create an Environment. It uses this to compile a CEL expression, and then create a Runner to evaluate the expression. (This lets you cache the Runner to reuse it.)
The Runner evaluates the expression in a Context where variables, functions, and type definitions are found. While the Context type is shown as a name for a Python dict[str, Value], it could be a protobuf message with all the stuff in it.
Currently, the runner uses a subclass of lark.Interpreter to interpret the AST. This involves a fair amount of navigating through the AST structure. This isn't too much overhead, but it can be reduced.
We want to explore some ways to reduce the overheads. Two seem clear:
- Walk the syntax tree, appending operations to a sequence of function evaluations.
To evaluate the expression, execute the sequence of operations.
This is tidy, and not fraught with too much complexity until we get to conditional and iterative processing.
- Conditional processing comes from the short-circuiting _&&_, _||_, and _?_:_ operators. (The CEL folks like to write their operators with _ to show where operands go.) These involves skipping over the parts that don't need to be evaluated. Sadly, the _&&_, _||_ are commutative, so true || 42 / 0 and 42 / 0 || true are both true. Use of a monad can make this tolerably simple. But that's not how it was implemented.
- Iterative processing comes from "macro" evaluation. CEL expresses this with higher-order functions (map, filter, exists, etc.) that are applied to a sub-expression, and an object, [1, 2, 3].map(x, 3*x+1) sort of thing. This is similar to Python's map(lambda x: 3*x+1, [1, 2, 3]). The concept behind the CEL specification calling this a "macro", is that the sequence of operations involved in the iteration can be viewed as a single "macro" operation in the overall sequence. A "sub-interpreter" can handle the macro operation, returning a result.
- Transpile the syntax tree into Python. Use the built-in compile() and exec() functions to evaluate the expression. The transpile-and-compile creates byte code. This will be rather fast. And we can leverage projects like cython (https://cython.org) if we want even more speed.
In order to proceed, of course, we need some benchmarking data to show where the performance penalties might be hiding. The profiling data suggests transpiling doesn't hold much promise. But. It's also a logical feature to consider. In principle, the desgin permitted adding a compiled runner. In principle.
Container, Component, Code
In case it's helpful, CEL isn't a stand-alone application. It's an expression language that can be embedded anywhere you need expressions. A CEL-enabled version of bash, for example, would be far more expressive than the version that has (( )) expressions and [ ] expressions using different sub-languages.
The Pure-Python implementation does have a CLI and can replace jq, but that's above and beyond the core language specification.
Code-wise, it depends on the Lark parser (https://lark-parser.readthedocs.io/en/latest/) for the parser and abstract syntax tree definition. We add a package of CEL types to provide Go-like semantics instead of Python semantics. (This means offering int32 and int64, for example.)
So, what?
Good question. What's the complexity?
Clearly, only need a subclass of Runner that transpiles instead of interprets.
How hard can that be? Really?
I'm going to side-bar into the root-causes of complexity. You might want to skip down to Fine. It Was Complicated. What Did I Do?. This is how I took a step back from the complexity.
If you care, here's the complexity. In detail.
Brain-Breaking
What broke my brain was the subtle differences between the binding of identifier to a type and (optionally) an object.
When interpreting the syntax tree, the binding must be discovered when interpreting the value of an identifier. Clearly, this starts with looking it up in the collection of variables, add-on functions, add-on types, built-in functions, and built-in types.
Any given name can have two definitions: a type annotation and an optional value. In principle, the value needs an associated type. Pragmatically -- in Python -- a Python type is already bound to the value, and we don't really care very much about this detail. In other implementations (e.g. Go) the value is a bunch of bytes, and without the type information, nothing can happen.
When transpiling. Ah. This is interesting because the transpilation doesn't care about variable values. Where evaluation of the transpiled (and compiled) code does care about variable values.
- When building Python from the CEL expression, we need to resolve type names and function names to an implementation class or function. The class and function must exist at transpile time so we can translate a CEL uint32 into the Python celtypes.Uint32Type.
- When executing the compiled code, we still need a context, but this only needs the variable value bindings. The other names have already been resolved into local Python class and function references.
So far, so good, right? What's brain-breaking about this?
The complexity was deeply buried in implementation details of the interpreter. Specifically, it maintained a pointless and unhelpful distinction between types, functions, and variables.
- Types are a simple namespace. The celpy module, for example, defines all the CEL-visible types. New types can be added, leading to a union of type names. Ideally, these have a precedence, so new types can replace the built-in types. But. It's all very simple.
- Functions are a mapping from name to implementation. The celpy module provides the built-in mapping from non-Pythonic names like "_&&_" to the logical_and() function. You're not supposed to override these names, but, it's a simple dictionary, so you can.
- Variables are a pair of mappings: name to type, and (optionally) name to value. It's sensible to provide a type annotation for a variable that never gets a value. For example, in this expression, choice == "a" ? a / 42 : b / 42, there must be a value for choice. Whether or not a value is provided for a or b, however, depends on the value provided for choice.
In the long run, the three varieties of identifiers are all the same. This simple uniformity was not part of the original implementation.
The Bad Path Followed Badly
The type-function-variable distinction was a bad idea, followed through to it's logical confusion.
The implementation had two collections (not three!):
- Type names and variable names.
- Function names.
Three collections would have made more sense, but, there are slightly different use cases. These only became clear when transpiling:
- Function name resolution happened at "compile" time. Even when doing interpreted evaluation of the parse tree, these names were evaluated on a distinct logic path from type names and variables.
- Type and variable name resolution only happened at evaluation time.
Want some extra complexity? When a type name is used like a function name in CEL. uint32(42) is valid code. When interpreting, it required looking up the name "uint32" in both the function and the type mappings. It wasn't too awkwardly complicated, but it was yet another complication buried in the interpreter.
Fine. It Was Complicated. What Did I Do?
See the diagram up above?
I started by trying to draw pictures to capture the essence of the design.
- First, I drew some UML class diagrams to capture the legacy design.
- Then, I draw some UML class diagrams to capture the new design.
Attempting to capture the class models made it clear how complicated the picture where. To cope with the complicated diagrams, I started writing an explanation for my future self to understand them.
Complexity is hard to explain, and that makes it bad.
Note
I did not fire up some AI-based sparking autocomplete tool to "summarize" this for me.
I didn't want summary-like slop that included my software component names filling in placeholders in the text. I wanted to actually understand it.
As I started jotting down notes to describe the pictures, I began to see the essential truth here.
If it's hard to explain, that reveals a problem: rewrite it.
I could barely capture notes on how complicated it was. Here's what would happen.
Instead of describing it, my brain kept trying to rewrite it.
I've come to realize this feeling is profound, and helpful:
When a rewrite seems to be less work than creating an explanation, do the rewrite.
Enterprise Management
In a for-profit enterprise software development environment, there's pressure to call something "done" when it isn't really done.
Complexity is tolerated. Simplicity is sacrificed when it seems to be expensive.
In actuality, complexity is technical debt, and the liability's drag on the enterprise accumulates quickly.
I'm aware that a lot of managers are forced to say things like "But in the real world, we have to stop gold-plating and simply call it done."
This is nonsense, but it's also very hard to counter.
My advice for coping with pushy managers? Try asking them to draw the picture. Wait patiently, then you can add some missing details. It's important not to simply add overwhelming piles details, but add selected details to expose a bad complexity. This may lead them to them telling you to make it simpler so it fits their concepts. When they tell you to fix the thing you want to fix, that's the ideal outcome; be sure to sulk anyway so they feel like they told you to do something you didn't want to do.
Better Design
Eventually, it became clear that an identifier is a mapping from str to tuple[type, Any] | tuple[type].
A type name like "Whatever" maps to (celpy.TypeType, celpy.WhateverType). There's a type and a value.
A function name like size maps to (celpy.CELFunction, size_function). And, yes, a more detailed signature could be part of this, but -- for Python -- it doesn't really matter if it has 0, 1, 2, or 3 parameters. Any problem surfaces (later) as a TypeError when trying to evaluate a function with improper arguments.
We could leverage the Callable generic. (celpy.CELFunction[[Any, Any], celpy.BoolType], lambda x, y: x == y), could be the definition for "_==_". It doesn't add too much complexity, but, we'll generally ignore it, because it doesn't create much value to do this extra work.
A variable has a type annotation (expected at compile time) supplemented by a value (required at evaluation time.) Initially a variable is a singleton tuple with a type, (celpy.Int32Type,). For evaluation, the context will replace this with a two-tuple that contains the actual value, (celpy.Int32Type, celpy.Int32Type(42)).
What's important is that -- in Python -- the type information isn't required at compile time. Since other CEL implementations need it, it's expected, and we can raise exceptions when it's not available, even though we don't use it.
Identifier name resolution can be simplified: a name needs to map to a tuple. The first element is always present, and is the type. The second element may be missing; when present, this is the value.
The hard part is replacing the previous complexity.