stingray.schema_instance¶
schema_instance – Schema and Navigation models
This module defines a number of foundational class hierarchies:
The
Schemastructure. The concept is to represent any schema as JSON Schema. From there, Stingray Reader can work with it. The JSON Schema can be used to provide validation of an instance.The
Instancehierarchy to support individual “rows” or “records” of a physical format. For delimited files (JSON, YAML, TOML, and XML) this is a native object. For non-delimited files, typified by COBOL, this is abytesorstr. For workbook files, this is alist[Any].The
Unpackerhierarchy to support Unpacking values from bytes, EBCDIC bytes, strings, navtive Python objects, and workbooks. In the case of COBOL, the unpacking must be done lazily to properly handleREDEFINESandOCCURS DEPENDING ONfeatures.A
Navhierarchy to handle navigation through a schema and an instance. This class allows theSchemaobjects to be essentially immutable and relatively abstract. All additional details are handled here.A
Locationhierarchy specifically to work with Non-Delimited objects represented asbytesorstrinstances.
A schema is used to unpack (or decode) the data in a file. Even a simple CSV file offers headings in the first row as a simplistic schema.
JSON Schema¶
A JSON Schema permits definitions used to navigate spreadsheet files, like CSV. It is also used to unpack more sophisticated generic structures in JSON, YAML, and TOML format, as well as XML.
A JSON Schema – with some extensions – can be used to unpack COBOL files, in Unicode or ASCII text as well as EBCDIC. Most of the features of a COBOL DDE definition parallel JSON Schema constructs.
COBOL has Atomic fields of type text (with vaious format details), and a variety of “Computational” variants. The most important is
COMP-3, which is a decimal representation with digits packed two per byte. The JSON Schema presumes types “null”, “boolean”, “number”, or “string” types have text representations that fit well with COBOL.The hierarchy of COBOL DDE’s is the JSON Schema “object” type.
The COBOL
OCCURSclause is the JSON Schema “array” type. The simple case, with a single, literalTIMESoption is expressed withmaxItemsandminItems.
While COBOL is more sophisticated than CSV, it’s generally comprarable to JSON/YAML/TOML/XML. There are some unique specializations related to COBOL processing.
COBOL Processing¶
The parallels between COBOL and JSON Schema permit translating COBOL Data Definition Entries (DDE’s) to JSON Schema constructs. The JSON Schema (with extensions) is used to decode bytes from COBOL representation to create native Python objects.
There are three areas of unique complex that require extensions.
The COBOL REDEFINES and OCCURS DEPENDING ON structures.
Additionally, EBCDIC unpacking is handled by stingray.estruct.
Redefines¶
A COBOL REDEFINES clause defines a free union of types for a given sequence of bytes. Within the application code,
there are generally fields that imply a more useful tagged union. The tags used for discrimination is not part of the
COBOL definition.
To make this work, each field within the JSON schema has an implied starting offset and length.
A COBOL REDEFINES clause can be described with a JSON Schema extension that includes a JSON Pointer to name a field with which a given field is co-located.
The COBOL language requires a strict backwards reference to a previously-defined field, and the names must have the name indentation level, making them peers within the same parent, reducing the need for complex pointers.
Occurs Depending On¶
The complexity of OCCURS DEPENDING ON constructs arises because the size (maxItems) of the array is the value of
another field in the COBOL record definition.
Ideally, a JSON Reference names the referenced field as the maxItems attribute for an array. This, however,
is not supported, so an extension vocabulary is required.
Notes¶
See https://json-schema.org/draft/2020-12/relative-json-pointer.html#RFC6901 for information on JSON Pointers.
Terminology¶
The JSON Schema specification talks about the data described by the schema as a “instance” of the schema. The schema is essentially a class of object, the data is an instance of that class.
It’s awkward to distinguish the more general use of “instance” from the specific use of “Instance of a JSON Schema”.
We’ll try to use Instance, and NDInstance to talk about the object described by a JSON Schema.
Physical File Formats¶
There are several unique considerations
for the various kinds of file formats.
These are implemented via the Unpacker
class hierarchy.
Delimited Files¶
Delimited files have text representations with syntax defined by a module like json. Because of the presence of delimiters, individual character and byte counting isn’t relevant.
Pythonic navigation through instances of delimited structures leverages the physical format’s parser output. Since most formats provide a mixture of dictionaries and lists, object[“field”] and object[index] work nicely.
The JSON Schema structure will parallel the instance structure.
Workbook Files¶
Files may also be complex binary objects described by workbook file for XLSX, ODS, Numbers, or CSV files. To an extent, these are somewhat like delimited files, since individual character and byte counting isn’t relevant.
Pythonic navigation through instances of workbook row structures leverages the workbook format’s parser output. Most workbooks are lists of cells; a schema with a flat list of properties will work nicely.
The csv fornmat is built-in. It’s more like a workbook than it is like JSON or TPOML. For example, with simple CSV files, the JSON Schema must be a flat list of properties corresponding to the columns.
Non-Delimited Files (COBOL)¶
It’s essential to provide Pythonic navigation through a COBOL structure. Because of REDEFINES clauses, the COBOL structure may not map directly to simple Pythonic dict and list types. Instead, the evaluation of each field must be strictly lazy.
This suggests several target constructs.
object.name("field").value()should catapult down through the instance to the named field. Syntactic sugar might includeobject["field"]orobject.field. Note that COBOL raises a compile-time error for a reference to an amiguous name; names may be duplicated, but the duplicates must be disambiguated withOFclauses.object.name("field").index(x).value()works when the field is a member of an array somewhere above it in the structure. Syntactic sugar might includeobject["field"][x]orobject.field[x].
These constructs are abbreviations for explicit field-by-field navigation. The field-by-field navigation involves explicitly naming all parent fields. Here are some constructs.
object.name("parent").name("child").name("field").value()is the full navigation path to a nested field. This can beobject["parent"]["child"]["field"]. A more sophisticated parser for URL path syntax might also be supported.object.name["parent/child/field"].object.name("parent").name("child").index(x).name("field").value()is the full navigation path to a nesteed field with a parent occurs-depending-on clause. This can beobject["parent"]["child"][x]["field"]. A more sophisticated parser for URL path syntax might also be supported.object.name["parent/child/0/field"].
The COBOL OF construct provides parentage in reverse order. This means object.name("field").of("child").of("parent").value() is requred to parallel COBOL syntax. While unpleasant, it’s helpful to support this.
The value() method can be helpful to be explicit about locating a value. This avoids eager evaluation of REDEFINES alternatives that happen to be invalid.
An alternative to the value() method is to use built-in special names __int__(), __float__(), __str__(), __bool__() to do conversion to a primitive type; i.e., int(object.name["parent/child/field"]). Additional functions like asdict(), aslist(), and asdecimal() can be provided to handle conversion edge cases.
We show these as multi-step operations with a fluent interface. This works out well when a nagivation context object is associated with each sequence of object.name()..., object.index(), and object.of() operations. The first call in the sequence emits a navigation object; all subsequent steps in the fluent interface return navigation objects. The final value() or other special method refers back to the original instance container for type conversion of an atomic field.
Each COBOL navigation step involves two parallel operations:
Finding the definition of the named subschema within a JSON schema.
Locating the sub-instance for the item. This is a slice of the instance.
The instance is a buffer of bytes (or characters for non-COBOL file processing.) The overall COBOL record has a starting offset of zero. Each DDE has an starting offset and length. For object property navigation this is the offset to the named property that describes the DDE. For array navigation, this is the index to a subinstance within an array of subinstances.
It’s common practice in COBOL to use a non-atomic field as if it was atomic. A date field, for example, may have year, month, and day subfields that are rarely used independently. This means that JSON Schema array and object definitions are implicitly type: “string” to parallel the way COBOL treats non-atomic fields as USAGE IS DISPLAY.
decimal_places function¶
- stingray.schema_instance.decimal_places(digits: int, value: Any) Decimal¶
Quantizes a
Decimalvalue to the requested precision.This undoes mischief to currency values in a workbook.
>>> decimal_places(2, 3.99) Decimal('3.99')
- Parameters:
digits – number of digits of precision.
value – a numeric value.
- Returns:
a
Decimalvalue, quantized to the requested number of decimal places.
digit_string function¶
- stingray.schema_instance.digit_string(size: int, value: SupportsInt) str¶
Transforms a numeric value from a spreadsheet into a string with leading zeroes.
This undoes mischief to ZIP codes an SSN’s with leading zeroes in a workbook.
>>> digit_string(5, 1020) '01020'
- Parameters:
size – target size of the string
value – numeric value
- Returns:
string with the requested size.
Schema¶
Here is the extended JSON Schema definition. This is a translation of the various JSON Schema constructs into Python class definitions. These objects must be considered immutable. (Pragmatically, RefTo objects can be updated to resolve forward references.)
A Schema is used to describe an Instance.
For non-delimited instances, the schema requires additional Location information;
this must be computed lazily to permits OCCURS DEPENDING ON to work.
For delimited instances, no additional data is required, since the parser located all object
boundaries and did conversions to Python types. Similarly, for workbook instances, the
underlying workbook parser can create a row of Python objects.
The DependsOnArraySchema is an extension to handle references to another
field’s value to provide minItems and maxItems for an array.
This handles the COBOL OCCURS DEPENDING ON. This requires a reference to another
field which is a reference to another field instead of a simple value.
The COBOL REDEFINES clause is handled created a OneOf suite of alternatives
and using some JSON Schema “$ref” references to preserve the original, relatively flat
naming for an elements and the element(s) which redefine it.
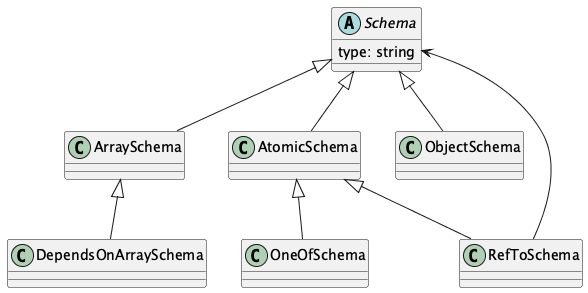
- class stingray.schema_instance.Schema(attributes: None | bool | int | float | str | list[Any] | dict[str, Any])¶
Base class for Schema definitions.
This wraps a JSONSchema definition, providing slightly simpler navigation via attribute names instead of dictionary keys.
s.typeinstead ofs['type'].It only works for a few attribute values in use here. It’s not a general
__getattribute__wrapper.Generally, these should be seen as immutable. To permit forward references, the RefTo subclass needs to be mutated.
- property attributes: None | bool | int | float | str | list[Any] | dict[str, Any]¶
Extract the dictionary of attribute values.
- Returns:
dict of keywords from this schema.
- dump_iter(nav: Nav | None, indent: int = 0) Iterator[tuple[int, Schema, tuple[int, ...], Any | None]]¶
Navigate into a schema using a
Navobject to provide unpacker, location and instance context.- Parameters:
nav – The
Navhelper with unpacker, location, and instance details.indent – Identation for nested display
- Yields:
tuple with nesting, schema, indices, and value
- json() None | bool | int | float | str | list[Any] | dict[str, Any]¶
Return the attributes as a JSON structure.
- print(indent: int = 0, hide: set[str] = {}) None¶
A formatted display of the nested schema.
- Parameters:
indent – Indentation level
hide – Attributes to hide because they’re contained within this as children
- property type: str¶
Extract the type attribute value.
- Returns:
One of the JSON Schema ‘type’ values.
- class stingray.schema_instance.ArraySchema(attributes: None | bool | int | float | str | list[Any] | dict[str, Any], items: Schema)¶
Schema for an array definition.
- dump_iter(nav: Nav | None, indent: int = 0) Iterator[tuple[int, Schema, tuple[int, ...], Any | None]]¶
Navigate into a schema using a
Navobject to provide unpacker, location and instance context.- Parameters:
nav – The
Navhelper with unpacker, location, and instance details.indent – Identation for nested display
- Yields:
tuple with nesting, schema, indices, and value
- property items: Schema¶
Returns the items sub-schema.
- Returns:
The sub-schema for the items in this array.
- property maxItems: int¶
Returns a value for maxItems. For simple arrays, this is the maxItems value. The
DependsOnArraySchemasubclass will override this.
- print(indent: int = 0, hide: set[str] = {}) None¶
A formatted display of the nested schema.
- Parameters:
indent – Indentation level
hide – Attributes to hide because they’re contained within this as children
- class stingray.schema_instance.AtomicSchema(attributes: None | bool | int | float | str | list[Any] | dict[str, Any])¶
Schema for an atomic element.
- class stingray.schema_instance.DependsOnArraySchema(attributes: None | bool | int | float | str | list[Any] | dict[str, Any], items: Schema, ref_to: Schema | None)¶
Schema for an array with a size that depends on another field. An extension vocabulary includes a “maxItemsDependsOn” attribute has a reference to another field in this definition.
- class stingray.schema_instance.ObjectSchema(attributes: None | bool | int | float | str | list[Any] | dict[str, Any], properties: dict[str, Schema])¶
Schema for an object with properties.
- dump_iter(nav: Nav | None, indent: int = 0) Iterator[tuple[int, Schema, tuple[int, ...], Any | None]]¶
Navigate into a schema using a
Navobject to provide unpacker, location and instance context.- Parameters:
nav – The
Navhelper with unpacker, location, and instance details.indent – Identation for nested display
- Yields:
tuple with nesting, schema, indices, and value
- print(indent: int = 0, hide: set[str] = {}) None¶
A formatted display of the nested schema.
- Parameters:
indent – Indentation level
hide – Attributes to hide because they’re contained within this as children
- class stingray.schema_instance.OneOfSchema(attributes: None | bool | int | float | str | list[Any] | dict[str, Any], alternatives: list[Schema])¶
Schema for a “oneOf” definition. This is the basis for COBOL
REDEFINES.- dump_iter(nav: Nav | None, indent: int = 0) Iterator[tuple[int, Schema, tuple[int, ...], Any | None]]¶
Navigate into a schema using a
Navobject to provide unpacker, location and instance context.- Parameters:
nav – The
Navhelper with unpacker, location, and instance details.indent – Identation for nested display
- Yields:
tuple with nesting, schema, indices, and value
- print(indent: int = 0, hide: set[str] = {}) None¶
A formatted display of the nested schema.
- Parameters:
indent – Indentation level
hide – Attributes to hide because they’re contained within this as children
- property type: str¶
Returns an imputed type of “oneOf”. The actual JSON Schema doesn’t use the “type” keyword for these.
- Returns:
Literal[“oneOf”]
- class stingray.schema_instance.RefToSchema(attributes: None | bool | int | float | str | list[Any] | dict[str, Any], ref_to: Schema | None)¶
Must deference type and attributes properties.
- property attributes: None | bool | int | float | str | list[Any] | dict[str, Any]¶
Deference the anchor name and return the attributes.
- dump_iter(nav: Nav | None, indent: int = 0) Iterator[tuple[int, Schema, tuple[int, ...], Any | None]]¶
Navigate into a schema using a
Navobject to provide unpacker, location and instance context.- Parameters:
nav – The
Navhelper with unpacker, location, and instance details.indent – Identation for nested display
- Yields:
tuple with nesting, schema, indices, and value
- property type: str¶
Deference the anchor name and return the type.
- class stingray.schema_instance.SchemaMaker¶
Build a
Schemastructure from a JSON Schema document.This doesn’t do much, but it allows us to use classes to define methods that apply to the JSON Schema constructs instead of referring to them as the source document dictionaries.
This relies on an
maxItemsDependsOnextension vocabulary to describeOCCURS DEPENDING ON.All
$refnames are expected to refer to explicit$anchornames within this schema. Since anchor names may occur at the end, in a#defsection, we defer the forward references and tweak the schema objects.- classmethod from_json(source: None | bool | int | float | str | list[Any] | dict[str, Any]) Schema¶
Build a
Schemafrom a JSONSchema document. This walks the hierarchy and resolves the$refreferences.- Parameters:
source – A JSONSchema document.
- Returns:
A
Schema.
- resolve(schema: Schema) Schema¶
Resolve forward
$refreferences.This is not invoked directly, it’s used by the
from_json()method.- Parameters:
schema – A
Schemadocument that requires fixup Generally, this must be the schema created bywalk(). ThisSchemaMakerinstance has a cache of$anchornames used for resolution.- Returns:
A
Schemadocument after fixing references.
- walk_schema(source: None | bool | int | float | str | list[Any] | dict[str, Any], path: tuple[str, ...] = ()) Schema¶
Recursive walk of a JSON Schema document, create
Schemaobjects for each schema and all of the children sub-schema.This is not invoked directly. It’s used by the
from_json()method.Relies on an
maxItemsDependsOnextension to describeOCCURS DEPENDING ON.Builds an anchor name cache to resolve “$ref” after an initial construction pass.
- Parameters:
source – A valid JSONSchema document.
path – The Path to a given property. This starts as an empty tuple. Names are added as properties are processed.
- Returns:
A
Schemaobject.
- class stingray.schema_instance.Reference(*args, **kwargs)¶
Instance¶
For bytes and strings, we provide wrapper Instance definitions.
These BytesInstance and TextInstance
are used by NDNav and Location objects.
For DInstance and WBInstance, however, we don’t
really need any additional features. We can use native JSON or list[Any]
objects.
- class stingray.schema_instance.WBInstance(*args, **kwargs)¶
CSV files are
list[str]. All other workbooks tend to belist[Any]because their unpacker modules do conversions.We’ll tolerate any sequence type.
- class stingray.schema_instance.DInstance(source: None | bool | int | float | str | list[Any] | dict[str, Any])¶
JSON/YAML/TOML documents are wild and free. Pragmatically, we want o supplement these classes with methods that emit
DNavobjects to manage navigating an object and a schema in parallel.
- class stingray.schema_instance.NDInstance(source: AnyStr)¶
The essential features of a non-delimited instance. The underlying data is
AnyStr, either bytes or text.
- class stingray.schema_instance.BytesInstance¶
Fulfills the protocol for an
NDInstance, useful forEBCDICandStructUnpackerUnpackers.To create an
NDNav, this object requires two things: - A Schema used to create Location objects. - An NonDelimited subclass of Unpacker to provide physical format details like size and unpacking.>>> schema = SchemaMaker.from_json({"type": "object", "properties": {"field-1": {"type": "string", "cobol": "PIC X(12)"}}}) >>> unpacker = EBCDIC() >>> data = BytesInstance('blahblahblah'.encode("CP037")) >>> unpacker.nav(schema, data).name("field-1").value() 'blahblahblah'
The
Sheet.row_iter()buildRowobjects that wrap an unpacker, schema, and instance.
- class stingray.schema_instance.TextInstance¶
Fulfills the protocol for an
NDInstance. Useful forTextUnpacker.To create an
NDNav, this object requires two things: - A Schema which populates the Location objects. - An NonDelimited subclass of Unpacker to provide physical format details like size and unpacking.>>> schema = SchemaMaker.from_json({"type": "object", "properties": {"field-1": {"type": "string", "cobol": "PIC X(12)"}}}) >>> unpacker = TextUnpacker() >>> data = TextInstance('blahblahblah') >>> unpacker.nav(schema, data).name("field-1").value() 'blahblahblah'
The
Sheet.row_iter()buildRowobjects that wrap an unpacker, schema, and instance.
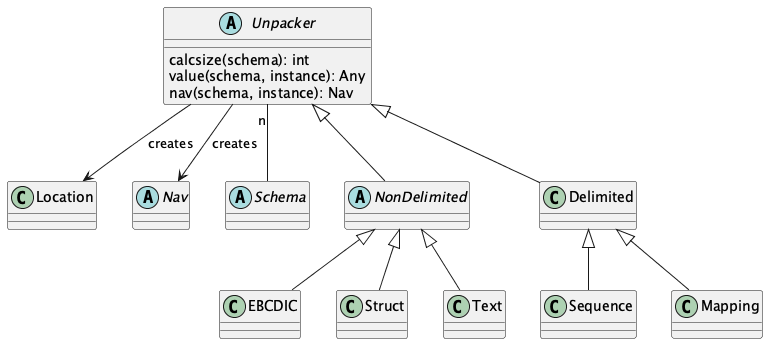
Unpacker¶
An Unpacker is a strategy class that handles details of physical unpacking of bytes or text. We call it an Unpacker, because it’s similar to struct.unpack.
The JSON Schema’s intent is to depend on delimited files, using a separate parser. For this application, however, the schema is used to provide information to the parser.
To work with the variety of instance data, we have several subclasses of Instance and related Unpacker classes:
Non-Delimited. These cases use
Locationobjects. We define anNDInstanceas a common protocol wrapped aroundAnyStrtypes. There are three sub-cases depending on the underlying object.COBOL Bytes. An
NDInstancetype union includesbytes. Theestructmodule is a COBOL replacement for thestructmodule. The JSON Schema requires extensions to handle COBOL complexities.STRUCT Bytes. An
NDInstancetype union includesbytes. Thestructmoduleunpack()andcalcsize()functions are used directly. This means the field codes must match thestructmodule’s definitions. This can leverage some of the same extensions as COBOL requires.Text. An
NDInstancetype union includesstr. This is the case with non-delimited text that has plain text encodings for data. The DISPLAY data will be ASCII or UTF-8, and any COMP/BINARY numbers are represented as text.
Delimited. These cases do not use
Locationobjects. There are two sub-cases:JSON Objects. This is a Union of
dict[str, Any] | Any | list[Any]. The instance is created by some external unpacker, and is already in a Python native structure. Unpackers includejson,toml, andyaml. A wrapper around anxmlparser can be used, also. We’ll use aJSONtype hint for objects this unpacker works with.Workbook Rows. These include CSV, ODS, XLSX, and Numbers documents. The instance is a structure created by the workbook module as an unpacker. The
csvunpacker is built-in. These all uselist[Any]for objects this unpacker works with.
Unpacking is a plug-in strategy.
For non-delimited data, it combines some essential location information with a value() method that’s unique to the instance source data.
For delimited data, it provides a uniforma interface for the various kinds of spreadsheets.
The JSON Schema extensions to drive unpacking include the “cobol” keyword. The value for this has the original COBOL DDE. This definition can have USAGE and PICTURE clauses that define how bytes will encode the value.
Implementation Notes¶
We need three separate kinds of Unpacker subclasses to manage the kinds of Instance subclasses:
The
NonDelimitedsubclass ofUnpackerhandles anNDInstancewhich is either a string or bytes with non-delimited data. TheLocationreflects an offset into theNDInstance.The
Delimitedsubclass ofUnpackerhandles delimited data, generally usingJSONas a type hint. This will have a dict[str, Any] | list[Any] | Any structure.A
Workbooksubclass ofUnpackerwraps a workbook parser creating aWBInstance. Generally workbook rows are list[Any] structures.
An Unpacker instance is a factory for Nav objects. When we need to navigate around
an instance, we’ll leverage unpacker.nav(schema, instance). Since the
schema binding doesn’t change very often, nav = partial(unpacker.nav, (schema,)) is
a helpful simplification. With this partial, nav(instance).name(n) or nav(instance).index(n) are all that’s needed
to locate a named field or apply array indices.
Unpacker Size Computations¶
The sizes are highly dependent on format information that comes from COBOL DDE (or other schema details.) A cobol extension to JSON Schema provides the COBOL-syntax USAGE and PICTURE clauses required to parse bytes. There are four overall cases, only two of which require careful size computations.
Non-Delimited COBOL. See https://www.ibm.com/docs/en/cobol-zos/4.2?topic=clause-computational-items and https://www.ibm.com/docs/en/cobol-zos/4.2?topic=entry-usage-clause and https://www.ibm.com/docs/en/cobol-zos/4.2?topic=entry-picture-clause.
USAGE DISPLAY.PIC X...orPIC A.... Data is text. Size given by the picture. Value isstr.USAGE DISPLAY.PIC 9.... Data is “Zoned Decimal” text. Size given by the picture. Value isdecimal.USAGE COMPorUSAGE BINARYorUSAGE COMP-4.PIC 9.... Data is bytes. Size based on the picture: 1-4 digits is two bytes. 5-9 digits is 4 bytes. 10-18 is 8 bytes. Value is aint.USAGE COMP-1.PIC 9.... Data is 32-bit float. Size is 4. Value isfloat.USAGE COMP-2.PIC 9.... Data is 64-bit float. Size is 8. Value isfloat.USAGE COMP-3orUSAGE PACKED-DECIMAL.PIC 9.... Data is two-digits-per-byte packed decimal. Value is adecimal.
Non-Delimited Native. Follows the Python struct module definitions. The struct.calcsize() function computes the structure’s size. The struct.unpack() function unpacks the values using the format specification. Or maxLength can be used to define sizes.
Delimited. The underlying parser (JSON, YAML, TOML, XML) decomposed the data and performed conversions. The schema conversions should match the data that’s present
Workbook. Generally, an underlying workbook unpacker is required. For CSV, the data is all strings, conversions are defined only in the schema.
Conversions¶
The CONVERSION mapping has values for the “conversion” keyword.
Some of these are extensions that could also be part of a vocabulary for COBOL and Workbooks.
Date, Time, Timestamp, Duration, and Error may need to be part of these conversions.
The problem with non-ISO standard dates means that a package like dateutil is required
to guess at the format.
For US ZIP codes, a digit_string(size, value) function turns an integer to a string padded with zeroes.
The partial function digits_5 = partial(digit_string, 5) is used to transforms spreadsheet zip
codes from integers back into useful strings.
For currency in many countries, a decimal_places() function will transform a float value back to Decimal
with an appropriate number of decimal places. The partial function decimal_2 = partial(decimal_places, 2)
will transform float dollars into a decimal value rounded to the nearest penny
- class stingray.schema_instance.Mode¶
Two handy constants used to by Unpackers to open files.
- BINARY = 'rb'¶
Binary mode file open
- TEXT = 'r'¶
Text mode file open
- class stingray.schema_instance.Unpacker¶
An Unpacker helps convert data from an
Instance. For NDInstances, this involves size calculations and value conversions. For WBInstances and JSON, this is a pass-through because the sizes don’t matter and the values are already Native Python objects.An Unpacker is a generic procotol. A class that implements the protocol should provide all of the methods.
It might make sense to define one more method
- instance_iter(self, sheet: str, **kwargs: Any) Iterator[Instance]¶
Iterates through all the records of a given sheet.
There doesn’t seem to be a way to sensibly defined here. There are too many variations on the instance types.
- calcsize(schema: Schema) int¶
Compute the size of this schema item.
- Parameters:
schema – A schema item to unpack
- Returns:
The size
- close() None¶
File close. This is generally delegated to a workbook module.
Creates a
Navhelper to locate items within this instance.- Parameters:
schema – Schema to apply.
instance – Instance to navigate into
- Returns:
A subclass of
Navappropriate to this unpacker.
- open(name: Path, file_object: IO | None = None) None¶
File open. This is generally delegated to a workbook module.
- Parameters:
name –
Pathto the file.file_object – Optional IO object in case the file is part of a ZIP archive.
- sheet_iter() Iterator[str]¶
Yields all the names of sheets of a workbook. In the case of CSV or NDJSON files or COBOL files, there’s only one sheet.
- Yields:
string sheet names.
- used(count: int) None¶
Provide feedback to the unpacker on how many bytes an instance actually uses.
This is for
RECFM=Nkinds of COBOL files where there are no RDW headers on the records, and the size must be deduced from the number of bytes actually used.- Parameters:
count – bytes used.
- class stingray.schema_instance.Delimited¶
An Abstract Unpacker for delimited instances, i.e.
JSONdocuments.An instance will be
list[Any] | dict[str, Any] | Any. It will is built by a separate parser, oftenjson, YAML, or TOML.For JSON/YAML/TOML, the instance should have the same structure as the schema. JSONSchema validation can be applied to confirm this.
For XML, the source instance should be transformed into native Python objects, following a schema definition. A schema structure may ignore XML tags or extract text from a tag with a mixed content model.
The sizes and formats of delimited data don’t matter: the
calcsize()function returns 1 to act as a position in a sequence of values.Concrete subclasses include open, close, and instance_iter.
- calcsize(schema: Schema) int¶
Computes the size of a field. For delimited files, this isn’t relevant.
- Parameters:
schema – The field definition.
- Returns:
Literal[1].
Create a
DNavhelper to navigate through anDInstance.- Parameters:
schema – The schema for this instance
instance – The instance
- Returns:
an
DNavhelper.
- value(schema: Schema, instance: DInstance) Any¶
Computes the value of a field in a given
DInstance. The underlying parser for delimited data has already created Python objects.If the
conversionkeyword was used in the schema, this conversion function is applied.- Parameters:
schema – The schema
instance – The instance
- Returns:
The instance
- class stingray.schema_instance.EBCDIC¶
Unpacker for Non-Delimited EBCDIC bytes.
Uses
estructmodule for calcsize and value of Big-Endian, EBCDIC data. This requires the “cobol” and “conversion” keywords, part of the extended vocabulary for COBOL. A “cobol” keyword gets Usage and Picture values required to decode EBCDIC. A “conversion” keyword converts to a more useful Python type.This assumes the COBOL encoded numeric can be
"type": "string"with additional"contentEncoding"details.This class implements a
"contentEncoding"using values of “packed-decimal”, and “cp037”, to unwind COBOL Packed Decimal and Binary as strings of bytes.- calcsize(schema: Schema) int¶
Computes the size of a field.
- Parameters:
schema – The field definition.
- Returns:
The size.
- close() None¶
A file close suitable for most COBOL files.
- instance_iter(sheet: str, recfm_class: Type[RECFM_Reader], lrecl: int, **kwargs: Any) Iterator[NDInstance]¶
Yields all of the record instances in this file.
Delegates the details of instance iteration to a
estruct.RECFM_Readerinstance.- Parameters:
sheet – The name of the sheet to process; for COBOL files, this is ignored.
recfm_class – a subclass of
estruct.RECFM_Readerlrecl – The expected logical record length of this file. This is used for RECFM without RDW’s.
kwargs – Additional args provided to the
estruct.RECFM_Readerinstance that’s created.
- Yields:
NDInstancefor each record in the file.
Create a
NDNavhelper to navigate through anNDInstance.- Parameters:
schema – The schema for this instance
instance – The instance
- Returns:
an
NDNavhelper.
- open(name: Path, file_object: IO | None = None) None¶
A file open suitable for unpacking an EBCDIC-encoded file.
- Parameters:
name – The
Pathfile_object – An open
- sheet_iter() Iterator[str]¶
Yields one name for the ‘sheet’ in this file.
- Yields:
Literal[“”]
- used(count: int) None¶
This is used by a client application to provide the number of bytes actually used.
This is delegated to the recfm_parser.
- Parameters:
count – number of bytes used.
- value(schema: Schema, instance: NDInstance) Any¶
Computes the value of a field in a given
NDInstance.- Parameters:
schema – The field definition.
instance – The instance to unpack.
- Returns:
The value.
- class stingray.schema_instance.Struct¶
Unpacker for Non-Delimited native (i.e., not EBCDIC-encoding) bytes.
Uses built-in
structmodule for calcsize and value.- calcsize(schema: Schema) int¶
Computes the size of a field.
- Parameters:
schema – The field definition.
- Returns:
The size.
- close() None¶
A file close suitable for most COBOL files.
- instance_iter(sheet: str, lrecl: int = 0, **kwargs: Any) Iterator[NDInstance]¶
Yields all the record instances in this file.
Delegates the details of instance iteration to a
estruct.RECFM_Readerinstance.- Parameters:
sheet – The name of the sheet to process; for COBOL files, this is ignored.
lrecl – The expected logical record length of this file. Since there are no delimiters, this is the only way to know how long each record is.
- Yields:
NDInstancefor each record in the file.
Create a
NDNavhelper to navigate through anNDInstance.- Parameters:
schema – The schema for this instance
instance – The instance
- Returns:
an
NDNavhelper.
- open(name: Path, file_object: IO | None = None) None¶
A file open suitable for unpacking a bytes file.
- Parameters:
name – The
Pathfile_object – An open
- sheet_iter() Iterator[str]¶
Yields one name for the ‘sheet’ in this file.
- Yields:
Literal[“”]
- struct_format(schema: Schema) str¶
Computes the
structformat string for an atomic Schema object.- Parameters:
schema – Schema
- Returns:
str format for
struct
- used(count: int) None¶
This is used by a client application to provide the number of bytes actually used.
- Parameters:
count – number of bytes used.
- value(schema: Schema, instance: NDInstance) Any¶
Computes the value of a field in a given
NDInstance.- Parameters:
schema – The field definition.
instance – The instance to unpack.
- Returns:
The value.
- class stingray.schema_instance.TextUnpacker¶
Unpacker for Non-Delimited text values.
Uses string slicing and built-ins. This is for a native Unicode (or ASCII) text-based format. If utf-16 is being used, this is effectively a Double-Byte Character Set used by COBOL.
A universal approach is to include
maxLength(optionallyminLength) attributes on each field.maxLength== the length of the field ==minLength.While it’s tempting to use “type”: “number” on this text data, it can be technically suspicious. If file has strings, conversions may part of the application’s use of the data, not the data itself. We use a “conversion” keyword to do these conversions from external string to internal Python object.
For various native bytes formats, this is a {“type”: “string”, “contentEncoding”: “struct-xxx”} where the Python
structmodule codes are used to define the number of interpretation of the bytes.For COBOL, the “cobol” keyword provides USAGE and PICTURE. This defines size. In this case, since it’s not in EBCDIC, we can use
structto unpack COMP values.This requires the “cobol” and “conversion” keywords, part of the extended vocabulary for COBOL. A “cobol” keyword gets Usage and Picture values required to decode EBCDIC. A “conversion” keyword converts to a more useful Python type.
(An alternative approach is to use the
patternattribute to provide length information. This is often {“type”: “string”, “pattern”: “^.{64}$”} or similar. This can provide a length. Because patterns can be hard to reverse engineer, we don’t use this.)- calcsize(schema: Schema) int¶
Computes the size of a field.
- Parameters:
schema – The field definition.
- Returns:
The size.
- close() None¶
A file close suitable for most COBOL files.
- instance_iter(sheet: str, **kwargs: Any) Iterator[NDInstance]¶
Yields all the record instances in this file.
- Parameters:
sheet – The name of the sheet to process; for COBOL files, this is ignored.
kwargs – Not used.
- Yields:
Instances of rows. Text files are newline delimited.
Create a
NDNavhelper to navigate through anNDInstance.- Parameters:
schema – The schema for this instance
instance – The instance
- Returns:
an
NDNavhelper.
- open(name: Path, file_object: IO | None = None) None¶
A file open suitable for unpacking a Text COBOL file.
- Parameters:
name – The
Pathfile_object – An open
- sheet_iter() Iterator[str]¶
Yields one name for the ‘sheet’ in this file.
- Yields:
Literal[“”]
- value(schema: Schema, instance: NDInstance) Any¶
Computes the value of a field in a given
NDInstance.- Parameters:
schema – The field definition.
instance – The instance to unpack.
- Returns:
The value.
- class stingray.schema_instance.WBUnpacker¶
Unpacker for Workbook-defined values.
Most of WBInstances defer to another module for unpacking. CSV, however, relies on the
csvmodule, where the instance islist[str].While it’s tempting to use “type”: “number” on CSV data, it’s technically suspicious. The file has strings, and only strings. Conversions are part of the application’s use of the data, not the data itself. The schema can use the
"conversion"keyword to specify one of the conversion functions.- calcsize(schema: Schema) int¶
Computes the size of a field. For delimited files, this isn’t relevant.
- Parameters:
schema – The field definition.
- Returns:
Literal[1].
Create a
WBNavhelper to navigate through anWBInstance.- Parameters:
schema – The schema for this instance
instance – The instance
- Returns:
an
WBNavhelper.
- value(schema: Schema, instance: WBInstance) Any¶
Computes the value of a field in a given
DInstance.The underlying parser for the workbook has already created Python objects. We apply a final conversion to get from a workbook object to a more useful Python object.
The schema voculary extension “conversion” is used to locate a suitable conversion function.
- Parameters:
schema – The schema
instance – The instance
- Returns:
An instance with the conversion applied.
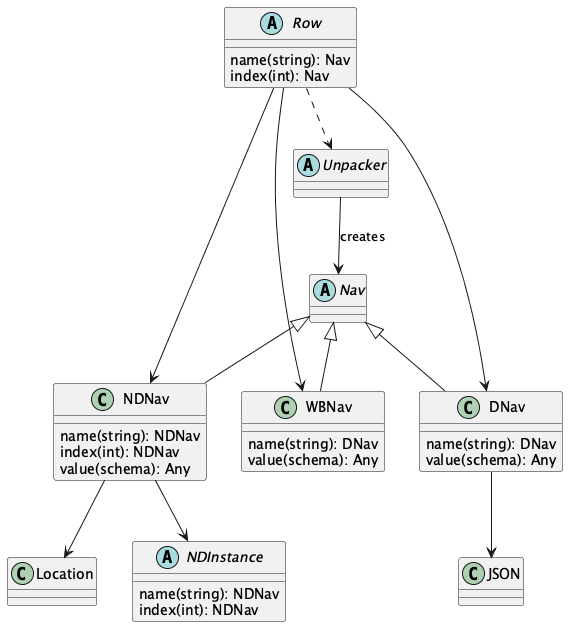
Schema and Instance Navigation¶
This is the core abstraction for a Row of a Sheet. Or a document in an JSON-Newline file. Or a row in a CSV file or other workbook. It’s one document in an interable YAML file. (While there’s no trivial mapping to TOML files, a subclass can locate sections or objects within a section that are treated as rows.)
A Row is a collection of named values. A Schema provides name and type information for unpacking the values. In the case of non-delimited file formats, navigation becomes a complex problem and Location objects are created. With COBOL REDEFINES and OCCURS DEPENDING ON clauses, fields are found in positions unique to each NDInstance.
The names for attributes should be provided as "$anchor" values to make them visible. In the case of simple workbook files, the rows are flat and property names are a useful surrogate for anchors.
A Row has a plug-in strategy for navigation among cells in the workbook or fields in a JSON object, or the more complex structures present in a Non-Delimited File.
The abstract Nav class provides unifieid navigation for delimited as well as non-delimited rows. The NDNav subclass handles non-delimited files where Location objects are required. The DNav handles JSON and other delimited structures. The WBNav subclass wraps workbook modules.
An NDNav instance provides a context that can help to move through an NDInstance of non-delimited data using a Schema. These are created by a LocationMaker instance because this navigation so intimately involved in creating Location objects to find structures.
A separate DNav subclass is a context that navigates through delimited objects where the object structure matches the schema structure. In the case of JSON/YAML/TOML, the operations are trivially delegated to the underlying native Python object; it’s already been unpacked.
A third WBNav subclass handles CSV, XML and Workbook files. These rely on an underlying unpacker to handle the details of navigation, which are specific to a parser. The WBNav is a Facade over these various kinds of parsers.
All of these are plug-in strategies used by a Row that provides a uniform wrapper.
We could try to create a subclass of dict that added methods to support Nav and DNav behaviors.
This seems a bit complicated, since we’re generally dealing with a Row.
This class creates an appropriate NDInstance or WBInstance based in the
Workbook’s Unpacker subclass.
A separate plug-in Strategy acts as an Adapter over the distinct implementation details.
Helper to navigate into items by field name or index into an array.
For Non-Delimited instances, names as well as indices are required for object and array navigation. Further, a
Locationis also required.For Delimited instances, a name or an index can be used, depending on what the underlying Python Instance object is. Dictionaries use names, lists use indices.
For Workbook instances, we only know the cells of a row by name in the schema and convert to a position.
A :py:class`Nav` is built by an
Unpacker:unpacker.nav(schema, instance)
This provides a common protocol for building navigation helpers.
A helpful dump of this schema and all subschema.
Navigate into an array by index.
- Parameters:
index – index
- Returns:
new
Navfor the indexed instance within items
Navigate into an object by name.
- Parameters:
name – name
- Returns:
new
Navfor the named subschema.
Returns the value of this instance.
- Returns:
Instance value.
Navigate through a
DInstanceusing aSchema. This is a wrapper around aJSONdocument.Note that these objects have an inherent ambiguity. A JSON document can have the form of a dictionary with names and values. The schema also names the properties and suggests types. If the two don’t agree, that’s an instance error, spotted by schema validation.
The JSON/YAML/TOML parsers have types implied by syntax and the schema also has types.
We need an option to validate the instance against the schema.
Prints this instance and all its children.
Locate the given index in an array.
Compute an offset into the array of items.
- Parameters:
index – the array index value
- Returns:
An DNav for the subschema of an item at the given index.
Locate the “$anchor” in this Object’s properties. Return a new
DNavfor the requested anchor or property name.- Parameters:
name – name of anchor
- Returns:
DNav for the subschema for the given property
The final Python value from the current schema. Consider refactoring to use Unpacker explicitly
- Returns:
Python object for the current instance.
Navigate through an
NDInstanceusingLocationas a helper.Prints this Location and all children.
Navigates a non-delimited Schema using
Location(based on the Schema) to expose values in the instance.
Locate the given index in an array.
Compute an offset into the array of items. Create a special
Locationfor the requested index value. The location, attribute, assigned tobase_location, is for index == 0.- Parameters:
index – the array index value
- Returns:
An NDNav for the subschema of an item at the given index.
Locate the “$anchor” in this Object’s properties and the related
Location. Return a newNDNavfor the requested anchor or property name.- Parameters:
name – name of anchor
- Returns:
NDNav for the subschema for the given property
Raw bytes (or text) from the current schema and location.
- Returns:
raw value from the current location.
Clone a piece of this instance as a new
NDInstanceobject. Since NDInstance is Union[BytesInstance, TextInstance], there are two paths: a new bytes or a new str.- Returns:
New
NDInstancefor this loocation.
Provide the schema.
- Returns:
Schema for the Location.
The final Python value from the current schema and location.
- Returns:
unpacked value from the current location.
Navigate through a workbook
WBInstanceusing aSchema.A Workbook Row is a
Sequence[Any]of cell values. Therefore, navigation by name translates to a position within theWBInstancerow.Prints this instance and all its children.
Locate the given index in an array.
Compute an offset into the array of items.
- Parameters:
index – the array index value
- Returns:
An WBNav for the subschema of an item at the given index.
Locate the “$anchor” in this Object’s properties. Return a new
DNavfor the requested anchor or property name.- Parameters:
name – name of anchor
- Returns:
WBNav for the subschema for the given property
The final Python value from the current schema.
- Returns:
value created by the Workbook unpacker
Locations¶
A Location is required to unpack bytes from non-delimited instances. This is a feature of the NonDelimited subclass of Unpacker and the associated NDNav class.
It’s common to consider the Location details as “decoration” applied to a Schema. An implementation that decorates the schema requires a stateful schema and cant process more than one Instance at a time.
We prefer to have Location objects as “wrappers” on Schema objects; the Schema remains stateless and we process multiple NDInstance objects with distinct Location objects.
Each Location object contains a Schema object and additional start and end offsets. This may be based on the values of dependencies like OCCURS DEPENDING ON and REDEFINES.
The abstract Location class is built by a LocationMaker object to provide specific offsets and sizes for non-delimited files with OCCURS DEPENDING ON. The LocationMaker seems to be part of the Unpacker class definition.
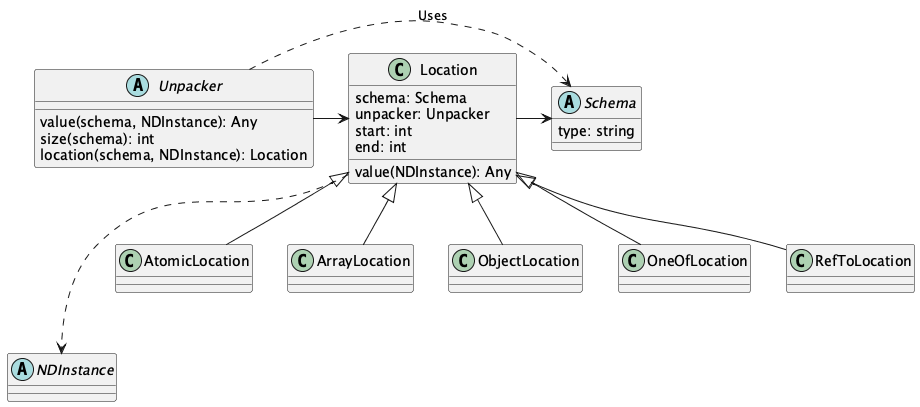
- class stingray.schema_instance.Location(schema: Schema, start: int, end: int = 0)¶
A Location is used to navigate within an
NDInstanceobjects.These are created by a
NDNavinstance.The
Unpacker[NDInstance]strategy is a subclass of NonDelimited, one of EBCDIC(), Struct(), or TextUnpacker().The value() method delegates the work to the
Unpackerstrategy.- abstract dump_iter(nav: NDNav, indent: int = 0) Iterator[tuple[int, Location, tuple[int, ...], bytes | None, Any]]¶
Dump this location and all children in the schema.
- Yields:
tuples of (indent, Location, array indices, raw bytes, value)
- abstract raw(instance: NDInstance, offset: int = 0) Any¶
The raw bytes of this location.
- property referent: Location¶
Most things refer to themselves. A RefToLocation, however, overrides this.
- abstract value(instance: NDInstance, offset: int = 0) Any¶
The value of this location.
- class stingray.schema_instance.ArrayLocation(schema: Schema, item_size: int, item_count: int, items: Location, start: int, end: int)¶
The location of an array of instances with the same schema. A COBOL
OCCURSitem.type(Schema) == ArraySchema.
- dump_iter(nav: NDNav, indent: int = 0) Iterator[tuple[int, Location, tuple[int, ...], bytes | None, Any]]¶
Dump the first item of this array location.
- Parameters:
nav – The parent
NDNavinstance with schema details.indent – The indentation level
- Yields:
tuples of (indent, Location, array indices, raw bytes, value)
- raw(instance: NDInstance, offset: int = 0) Any¶
Return the bytes of this location.
- Parameters:
instance – The Non-Delimited Instance
offset – The offset into the sequence
- Returns:
instance bytes (or characters if it’s a text instance.)
- value(instance: NDInstance, offset: int = 0) Any¶
Return the value of this location.
- Parameters:
instance – The Non-Delimited Instance
offset – The offset into the sequence
- Returns:
The Python object unpacked from this location
- class stingray.schema_instance.AtomicLocation(schema: Schema, start: int, end: int = 0)¶
The location of a COBOL elementary item.
type(Schema) == AtomicSchema.
- dump_iter(nav: NDNav, indent: int = 0) Iterator[tuple[int, Location, tuple[int, ...], bytes | None, Any]]¶
Dump this atomic location.
- Parameters:
nav – The parent
NDNavinstance with schema details.indent – The indentation level
- Yields:
tuples of (indent, Location, array indices, raw bytes, value)
- raw(instance: NDInstance, offset: int = 0) Any¶
Return the bytes of this location.
- Parameters:
instance – The Non-Delimited Instance
offset – The offset into the sequence
- Returns:
The raw bytes from this location
- value(instance: NDInstance, offset: int = 0) Any¶
For an atomic value, locate the underlying value. This may involve unpacking.
- Parameters:
instance – The Non-Delimited Instance
offset – The offset into the sequence
- Returns:
The Python object unpacked from this location
- class stingray.schema_instance.ObjectLocation(schema: Schema, properties: dict[str, Location], start: int, end: int)¶
The location of an object with a dictionary of named properties. A COBOL group-level item.
type(Schema) == ObjectSchema.
- dump_iter(nav: NDNav, indent: int = 0) Iterator[tuple[int, Location, tuple[int, ...], bytes | None, Any]]¶
Dump this object location and all the properties within it.
- Parameters:
nav – The parent
NDNavinstance with schema details.indent – The indentation level
- Yields:
tuples of (indent, Location, array indices, raw bytes, value)
- raw(instance: NDInstance, offset: int = 0) Any¶
Return the bytes of this location.
- Parameters:
instance – The Non-Delimited Instance
offset – The offset into the sequence
- Returns:
instance bytes (or characters if it’s a text instance.)
- value(instance: NDInstance, offset: int = 0) Any¶
Return the value of this location.
- Parameters:
instance – The Non-Delimited Instance
offset – The offset into the sequence
- Returns:
The Python object unpacked from this location
- class stingray.schema_instance.OneOfLocation(schema: Schema, alternatives: list[Location], start: int, end: int)¶
The location of an object which has a list of REDEFINES alternatives.
type(Schema) == OneOfSchema.
- dump_iter(nav: NDNav, indent: int = 0) Iterator[tuple[int, Location, tuple[int, ...], bytes | None, Any]]¶
Dump this object location and all the alternative definitions. Since some of these may raise exceptions, displays may be incomplete.
- Parameters:
nav – The parent
NDNavinstance with schema details.indent – The indentation level
- Yields:
tuples of (indent, Location, array indices, raw bytes, value)
- raw(instance: NDInstance, offset: int = 0) Any¶
Return the bytes of this location.
- Parameters:
instance – The Non-Delimited Instance
offset – The offset into the sequence
- Returns:
instance bytes (or characters if it’s a text instance.)
- value(instance: NDInstance, offset: int = 0) Any¶
Return the value of this location.
- Parameters:
instance – The Non-Delimited Instance
offset – The offset into the sequence
- Returns:
The Python object unpacked from this location
- class stingray.schema_instance.RefToLocation(schema: Schema, anchors: dict[str, Location], start: int, end: int)¶
Part of REDEFINES; this is the COBOL-visible name of a path into a
OneOfLocationalternative.type(Schema) == RefToSchema.
This could also be part of
OCCURS DEPENDING ON. If used like this, it would refer to the COBOL-visible name of an item with an array size. TheOCCURS DEPENDING ONdoesn’t formalize this, however.- dump_iter(nav: NDNav, indent: int = 0) Iterator[tuple[int, Location, tuple[int, ...], bytes | None, Any]]¶
These items are silenced – they were already displayed in an earlier OneOf.
- property properties: dict[str, Location]¶
Deference the anchor name and get the properties.
- Returns:
properties of the referred-to name.
- raw(instance: NDInstance, offset: int = 0) Any¶
Dereference the anchor name and return the bytes of this location.
- Parameters:
instance – The Non-Delimited Instance
offset – The offset into the sequence
- Returns:
instance bytes (or characters if it’s a text instance.)
- property referent: Location¶
Deference the anchor name and get the properties.
- Returns:
The Location referred to.
- value(instance: NDInstance, offset: int = 0) Any¶
Dereference the anchor name and return the value of this location.
- Parameters:
instance – The Non-Delimited Instance
offset – The offset into the sequence
- Returns:
The Python object unpacked from this location
- class stingray.schema_instance.LocationMaker(unpacker: Unpacker[NDInstance], schema: Schema)¶
Creates
Locationobjects to find sub-instances in a non-delimitedNDInstance.A
LocationMakerwalks through aSchemastructure applied to aNDInstanceto emitLocationobjects. This is based on the current values in the NDInstance, to support providing a properly-computed value forOCCURS DEPENDING ONarrays.This is based on an
NDUnpackerdefinition of the physical format of the file. It’s only used for non-delimited files where the underlying NDInstance is Union[bytes, str].This creates
NDNavisntances for navigation through Non-Delimited instances.The algorithm is a post-order traversal of the subschema to build Location instances that contain references to their children.
- from_instance(instance: NDInstance, start: int = 0) Location¶
Builds a
Locationfrom an non-delimited py:class:NDInstance.This will handle
OCCURS DEPENDING ONreferences and dynamically-sized arrays.- Parameters:
instance – The record instance.
start – The initial offset, usually zero.
- Returns:
a
Locationdescribing this instance.
- from_schema(start: int = 0) Location¶
Attempt to build a
Locationfrom a schema.This will raise an exception if there is an
OCCURS DEPENDING ON. For these kinds of DDE’s, an instance must be used.- Parameters:
start – The initial offset, usually zero.
- Returns:
a
Locationdescribing any instance of this schema.
Return a
NDNavnavigation helper for an Instance using an Unpacker and Schema.- Parameters:
instance – The non-delimited instance to navigate into.
- Returns:
an
NDNavprimed with location information unique to this instance.
- size(schema: Schema) int¶
Returns the overall size of a given schema.
The work is delegated to the
Unpacker.- Parameters:
schema – The schema to size.
- Returns:
The size
- walk(schema: Schema, start: int) Location¶
Recursive descent into a Schema, creating a
Location. This is generally used via thefrom_instance()method. It is not invoked directly.- Parameters:
schema – A schema describing a non-delimited
NDInstance`.start – A starting offset into the
NDInstance
- Returns:
a
Locationwith this item’s location and the location of all children or array items.
Exceptions¶
- class stingray.schema_instance.DesignError¶
This is a catastrophic design problem. A common root cause is a named REGEX capture clause that’s not properly handled by a class, method, or function.