We're talking about extracting data from complex relational databases. This is -- in a way -- another case study for my Unlearning SQL book.
In Part I, we loaded a database and queried the metadata. In Part II, we extracted the raw tables and loaded up a TAR Archive with NDJSON documents. In Part III, we prepared native Python objects that had a complete representation for the various kinds of tree structures. These include assets, categories, forum topics, image galleries, amongst other things.
We can now explore the details of the data, looking for the original content.
How Joomla! Works
We're avoiding looking at the Jooml! elephant, wandering around the parlor. Yes, we could reverse engineer the PHP to figure out how the database content is used to build the web site. We, however, don't much care about the details.
We have a pile of specific kinds of content we can see. This includes:
- A home page with a few articles.
- A right sidebar with some articles.
- A few pages with dozen or so narrowly-focused articles.
- The master collection of articles, neatly organized by category.
- Several separate pages of different kinds of links. These are actually articles with the links.
- The Kunena Forums.
- A Photo gallery that might be from RSGallery2 or JoomGallery.
- The Phoca Downloads.
While there are a bunch of Joomla! Modules that seem to be used to define the site organization, there is also a (simpler) tree of Assets. For the most part, it appears we need a "grep"-like tool to dig through the database looking for content. Then we can work out what appears to be the owning asset, bypassing many Joomla! complications.
Doing a grep on the raw data is actually kind of easy.
The "raw" database has the following type definition:
DBTable = list[db_model.DBModel] type Database = dict[str, DBTable]
We can, then, use database.values() to work all of the tables. And for each table, all of the string columns looking for relevant rows. It shapes up like this:
def row_match(pattern: Pattern, row: BaseModel) -> bool:
for name in row.model_fields_set:
val = getattr(row, name)
match val:
case str() as text if pattern.search(text):
return True
case _:
pass
return False
Since the rows are based on pydantic.BaseModel, we can introspect the columns and search the text-based columns to locate all rows that has a column matching the given pattern. We search all of them because there are columns with names like "title", "name", and "alias", all of which seem to have potentially relevant values, and we don't know precisely what the semantics of them are. Here's the containing function that wraps the row_match function:
@staticmethod
def execute(options: argparse.Namespace) -> None:
"""
Search all str columns of all tables for the pattern.
"""
# def row_match... (shown earlier)
database = load_db(options.source)
Grep.logger.info("grep pattern %r", options.pattern)
pattern = re.compile(options.pattern)
matcher = partial(row_match, pattern)
for cls in database:
# Could reuse :meth:`where` method for this
for match in filter(matcher, database[cls]):
print(type(match), shorten(repr(match), 128))
This is a method of a Grep command:
class Grep(Command):
"""Make a grep-like search through the content."""
logger = logging.getLogger("Grep")
@staticmethod
def config_argparse(
subparsers: argparse._SubParsersAction, defaults: dict[str, Any]
) -> None:
parsers_grep = subparsers.add_parser("grep", help="grep all tables for a Regex")
parsers_grep.add_argument("--pattern", "-p", action="store", type=str)
Command.common_args(parsers_grep, defaults)
parsers_grep.set_defaults(command=Grep.execute)
The abstract base class is defined like this:
class Command(abc.ABC):
"""CLI Command abstract base class."""
logger: logging.Logger
@staticmethod
@abc.abstractmethod
def config_argparse(
subparsers: argparse._SubParsersAction, defaults: dict[str, Any]
) -> None: ...
@staticmethod
def common_args(parser: argparse.ArgumentParser, defaults: dict[str, Any]) -> None:
parser.add_argument(
"source", action="store", type=Path, default=defaults.get("source")
)
@staticmethod
@abc.abstractmethod
def execute(options: argparse.Namespace) -> None: ...
This provides a tidy package to wrap the grep command so we can create a CLI to poke around in the database looking for the Home Page content, the various pages with narrowly-focused articles, and the specific articles with the links.
This isn't quite enough to locate all of the various forums and galleries. But it gets us started examining the content. There's more -- of course -- but it's all outside the realm of SQL processing.
The Path
There are several steps on this path:
- SQL legacy data.
- Python extract of SQL data.
- Python structures without SQL complications of foreign keys. And -- more important -- with proper hierarchies.
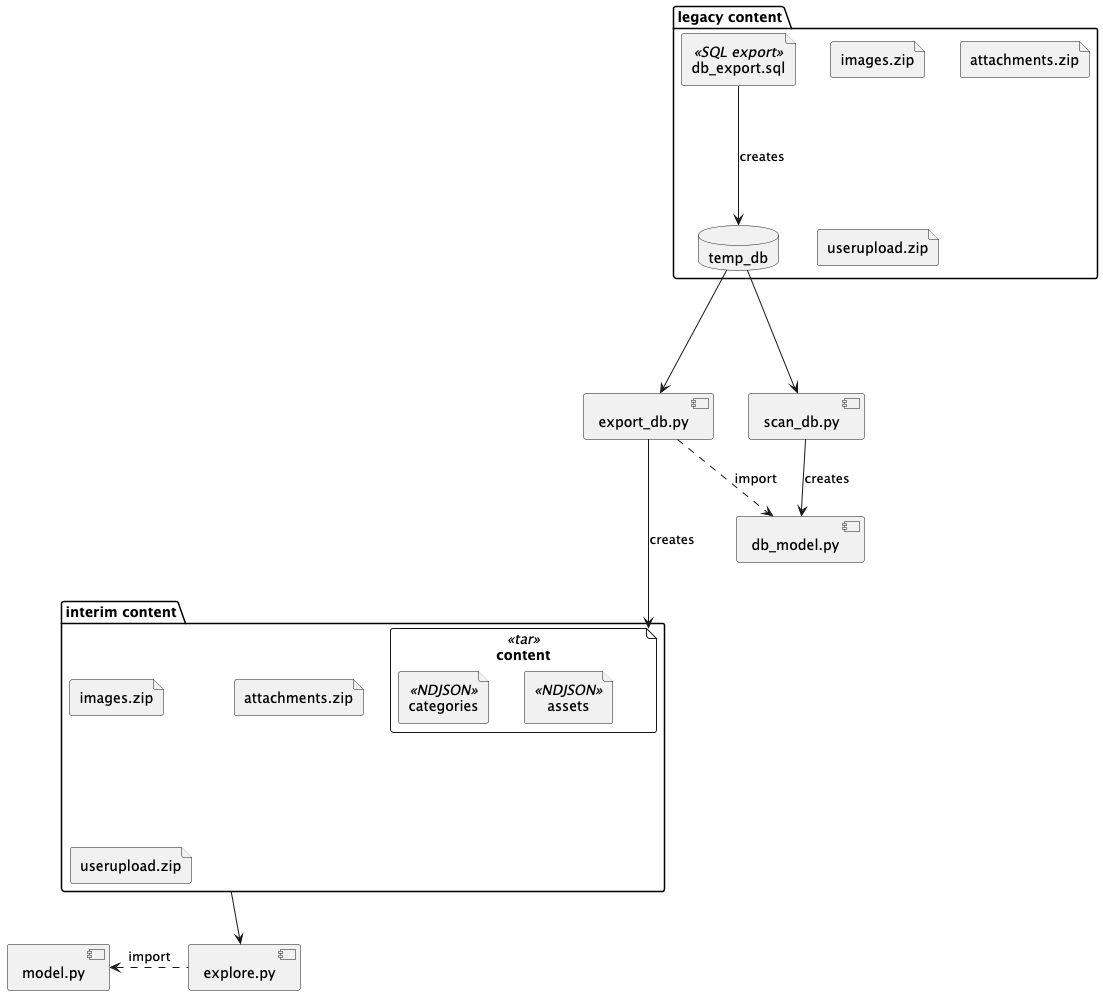
The migration path so far
These first few transformations aren't the goal, of course.
The goal is a directory tree of markdown and images that Hugo can transform into a static web site. The rest of the exploration and migration isn't SQL-related at all. It's a fairly complicated matter of finding the content and restating it in a form Hugo can work with.
Conclusion
We started with a SQL database, and carefully set it aside. We wrote two small applications to get the data out of the SQL database.
- scan_db.py -- extracts the table definitions and PlantUML descriptions from the database.
- extract_db.py -- extracts the data, writing a TAR file of NDJSON documents with all the database rows.
Once we had the data in a neutral form -- specifically NDJSON documents -- we could create alternative models for the data and preparation steps to populate those models.
This model is an integration part of exploring the data. This means the exploration application evolves until it becomes the migration application.
We start with a skeleton of view_content.py. This is based on a number of Builder classes and a prepare_content() function to get raw data organized into what appears to be a useful model.
The steps in this view_content.py application (and the association model.py) are free of SQL complications.
The conversion process has at least three parts:
- Locate the relevant objects. Often, an instance of the Assets class does this. A relevant Assets instance doesn't seem to be universal, though.
- Convert the objects for use by a static site generator like Hugo. This turns out to be pretty complicated. There are a number of distinct cases for the different kinds of content: articles, images, downloads, and forum topics. However, since we're done with SQL, these complications don't involve database queries.
- Write needed _index.md files so Hugo Sections and Page Bundles will mimic the legacy site's Joomla! presentation.