Recently, we talked about extracting data from complex relational databases. This is -- in a way -- another case study for my Unlearning SQL book. This is a description of what comes next after the "low-level" conversion. Warning: it's complicated.
BLUF: Take the time to get rid of SQL processing.
In Part I, we loaded a database and queried the metadata. In Part II, we extracted the raw tables and loaded up a TAR Archive with NDJSON documents. In Part III, we prepared native Python objects that had a complete representation for the various kinds of tree structures. These include assets, categories, forum topics, image galleries, amongst other things. In Part IV, we talked about some applications to examine the converted data, looking for useful values, keys, and relationships.
We're going to skip a lot of the icky Joomla! details and focus on how to create something potentially useful.
The Goal
Recall from Part IV, we thought we had several steaming heaps of content on the legacy site. After exploration, we think we have the following:
- A home page with a few articles.
- A right sidebar with two articles.
- A few content pages, each of which has links to a dozen or so narrowly-focused articles in a few categories.
- The master collection of articles, neatly organized by category. There's a hierarchy here, a SQL nightmare we've avoided by restructuring the data.
- The Kunena forums collection categories, topics, and messages. There's a hierarchy here, another SQL nightmare.
- The JoomGallery collection of images. Hierarchy.
- The Phoca collection of download files. You guessed it, another hierarchy.
These aren't the only hierarchues. Menus, modules, and assets have very tangled relationships, also. These are a SQL-query nightmare that we've turned into simple Python references among objects.
There's more, of course.
- A hoard of Yahoo message-board posts which are not first-class parts of Joomla! but are first-class content.
- Scans of the old paper newsletters. These, too, are not first-class parts of Joomla!, but are clearly very important content.
We'd like to dump all of this into a form that the Hugo tool can use to approximate the original site's content and structure. We're not going to spend too much time on the original look and feel; we can fuss with CSS to maybe match the color scheme.
What we've got are two separate kinds of things in the resulting site:
- The "pages" which are Hugo Page Bundles with an _index.md and maybe some image resources. Each article becomes a page. In the case of the Home page -- which has multiple articles plastered onto it -- we will need a special-case template to include the bodies of multiple articles in one place. The Yahoo! messages are -- essentially -- articles that require some extra effort to convert.
- The "collections" which are Hugo Sections, using an empty _index.md and a section-index generated by the template. The old newsletters are little more than downloads; these should be handled gracefully as a collection of Page Bundles.
We've also got some things we're going to set aside. Specifically, the right side-bar for articles is a waste of screen real-estate. It's not present for Forum or Photo Gallery.
Many of the Hugo themes have a 3-column look: the top-level menu is on the left, and the page table-of-contents is on the right. This seems to be somewhat more useful. One very spare Hugo theme is the Book theme, which seems like a good place to start.
The Processes
There are two separate kinds of migration processes:
Bulk migration of the collections. We have four, separate, unique subclasses.
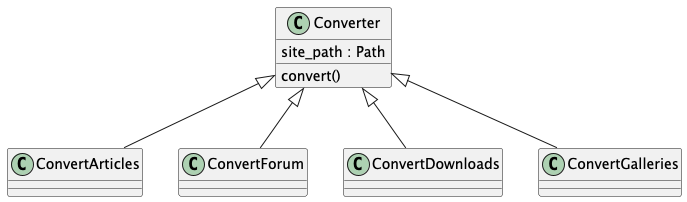
The Converter Class Hierarchy
Create the top-level pages that match the various pages of articles on the legacy site.
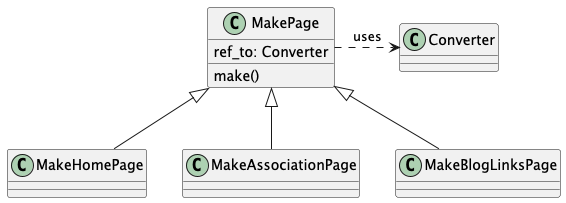
The MakePage Class Hierarchy
Note that the pages depend on the bulk-conversion results. The new path structure and new file names, and other details are (more-or-less) encapsulated in the converter classes.
Things That Aren't Easy
While Hugo handles a large number of special cases and exceptions gracefully, we have legacy content that's a bit of a mess. Some of the mess may be my inability to ferret out all of the details of the Joomla! data model. Other aspects of the mess also seem to be a result of the way Joomla! decides what's "published" and what's not "published."
First, and most obvious, we have HTML content. We can -- if we want -- generate HTML pages and leave the details to Hugo. In the long run, we'd like to move away from HTML. We'd really like to emphasize Markdown and make HTML an exception.
To do this, we state each page uses markdown, and wrap the HTML in {{<html>}}...{{</html>}} "short tags". This is -- well -- ugly. It sequesters the HTML in those few places where it's used.
- descriptions for galleries and downloads.
- articles.
- forum messages.
It means a lot of code like this:
print()
print("{{<html>}}", article.fulltext, "{{</html>}}")
This gets us started with "safe" HTML everywhere. We can see a great deal of the site with this hack.
Hugo leaves HTML comments in places where unsafe HTML shows up. We can look for <!-- raw HTML omitted --> in the generated HTML and include needed wrappers.
Embedded Images and Links
There are two kinds of links that show up in articles, descriptions, and forum messages:
- <a href="..."> tags
- <img src="..."> tags
These have a variety of forms:
- Proper external references with a scheme and/or a "netloc" (host name.)
- Redundant internal references with a scheme and netloc of the server currently hosting the legacy content.
- index.php?... queries.
- #fragment fragements of the current page.
- local/path/to/content paths into the legacy site content.
- userupload/whatever paths into the local directory tree outside what Joomla! manages.
These devolve to three functions for link rewriting algorithms.
- A filter to distinguish between "don't bother", "query", and "path" cases. A URL with a scheme or netloc (or both) is ignored. A URL that's only a fragment is also ignored. (We could try to clean up the fragments, but, there aren't many and they require divining the author's intent, something that's hard to automate.)
- A function to rewrite the Joomla! queries into paths into the new content structure.
- A function to examine the various paths that are used and restate these as part of the new content structure.
Because we have four kinds of collections, plus the local filesystem references, we have a number of "search" functions for this case:
- search galleries
- search articles
- search downloads
- search forums
- search image archive files
Yes. This is a large pain. While there is some overlap, each collection is unique with unique names and a distinct resulting tree in the new content. No, there's no trivial way to impose a single, unifying, "one-ring-to-rule-them-all" content structure. The whole point is to respect the unique features of each category of content.
What Else? Oh, Right, Section Index
The Book theme doesn't (by default) include section indexes as a default structure.
If there's a layout/_defaults/section.html, this is used for those _index.md pages that are clearly the top of a section tree.
We don't need to do anything more than define the template for the index. Here's what we started with:
{{ define "main" }}
<main>
{{ .Content }}
{{ $pages := .Sections }}
{{ $paginator := .Paginate $pages 25 }}
<ul>
{{ range $paginator.Pages }}
<li><a href="{{ .RelPermalink }}">{{ .LinkTitle }}</a></li>
{{ end }}
</ul>
{{ template "_internal/pagination.html" . }}
</main>
{{ end }}
This doesn't sort things properly, so we need to add metadata with weighting.
Finally, Broken Links
We have two origins for broken links.
- Stuff we couldn't find in the database. Or, more properly, things which appear to be named in the database, but we can't find anywhere.
- Stuff we thought we found, but it still didn't work in Hugo. These are essentially bugs, and we're still working through the last five.
The "stuff we could never find" includes things that were likely removed from the legacy site. Since we didn't take the time to work out all the "pubish this--don't publish that" rules, we've likely included things which were "unpublished" but not deleted.
Other things are <a href="href=">Something</a> kinds of HTML. That's just broken. There aren't many of these, and they need to be addressed manually.
Conclusion
Note the complexity of the migration.
There's not much that can be done to magically simplify all the special cases.
The time spent getting the database out of SQL and into Python objects gave us pleasantly simple Python objects to work with.
The class hierarchies evolved slowly. While it seems clear from the UML diagrams that these are "logical" designs, they didn't happen first. The initial design was not so clear and simple, leading to lots of redundant and inter-dependent code.
There's still a fair number of ultra-long methods that need to be decomposed into shorter, easier-to-understand methods. The remaining bugs involve two lost files and three index.php?... references that the link rewriter didn't handle correctly.